



Evolved structure of language shows lineage-specific trends in word-order universals
We have a new paper out in Nature showing that language structures show lineage-specific trends:
Dunn M, Greenhill SJ, Levinson SC, & Gray RD. 2011. Evolved structure of language shows lineage-specific trends in word-order universals. Nature.
The people involved in this paper were Dr. Michael Dunn, Dr. Simon Greenhill, Professor Stephen Levinson, Professor Russell Gray.
Background
One of the fundamental ways that languages vary is in the way they order words in clauses. There are about 7,000 extant languages, some with just a dozen contrastive sounds, others with more than 100, some with complex patterns of word formation, others with simple words only, some with the verb at the beginning of the sentence, some in the middle, and some at the end.
Some languages, like English, put the subject of the sentence before the verb and the object, e.g.
- The man (subject) put (verb) the dog (object) in the canoe.
Other languages like Welsh put the verb before the subject and the object, ending up with a sentence structured like:
- Put (verb) the man (subject) the dog (object) in the canoe.
There are a number of "word-order features" like this that control the construction of clauses. For example, most familiar western European languages have prepositions — the words like 'in' or 'on' that go before a noun phrase to give expressions like 'in the canoe'. But many languages instead use postpositions, so the speakers of these languages would say '(the) canoe on'.
This is an important question in linguistics — how do languages construct sentences and how do the structures they use co-vary. There are two major viewpoints about this:
-
Generative Linguistics:
Linguists following Noam Chomsky have argued that this variation is constrained by innate parameters that are set when we learn a language. For example, the setting 'heads first' will cause a language to put verbs before objects ('kick the ball'), and prepositions before nouns ('into the goal').
According to this theory languages only differ in the parameter settings and these word-order features must co-vary perfectly — all languages that place verbs before objects must place prepositions before nouns.
-
Statistical Universals:
In contrast linguistic typologists like Joseph Greenberg and Matthew Dryer have argued that these word-order features tend to cluster statistically, possibly to "harmonize" word order and convey information better, by emphasizing consistent direction of branching.
For example, Dryer (1992) suggested that languages that put verbs before objects tend to use prepositions and place genitives after the noun — as in the following figures:
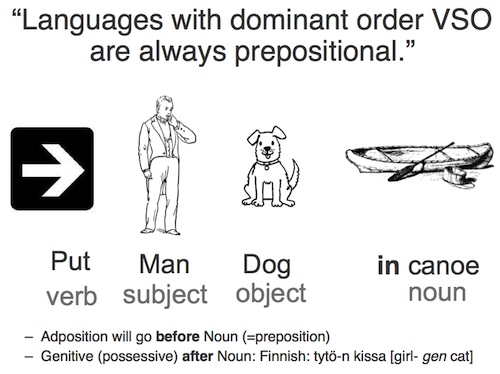
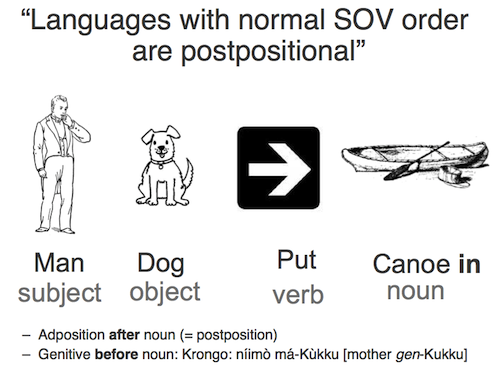
Some statistical word-order universals, showing the expected link between Object-Verb ordering and Adposition (Pre- or Post-Position) type.
What we did
In this study we tested how eight different word-order features have co-evolved in four of the world’s major language families: Austronesian, Indo-European, Bantu and Uto-Aztecan. Here's a map showing the languages we used:
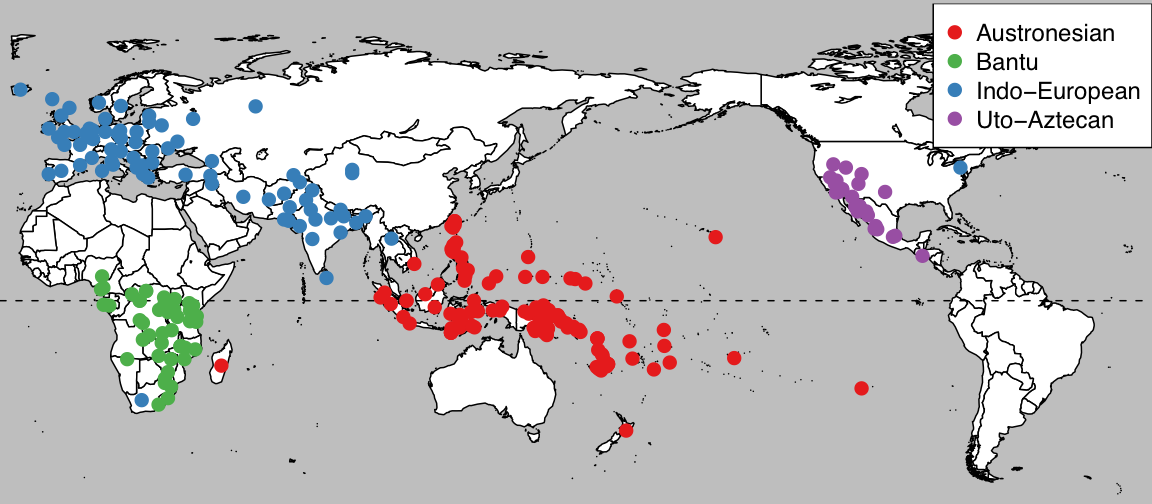
Map of languages analysed.
Step 1:
The first step was to build language family trees — phylogenies — from basic vocabulary data. We describe how these are built here. We can use these phylogenies as a scaffold for testing hypotheses about the coevolutionary links between these features.
Step 2:
We extracted data about eight different word-order features from the large online database the World Atlas of Language Structures, and added more information from other published sources. These features are:
- Order of Adjective and Noun
- Order of Adposition and Noun-Phrase
- Order of Demonstrative and Noun
- Order of Genitive and Noun
- Order of Numeral and Noun
- Order of Object and Verb
- Order of Relative Clause and Noun
- Order of Subject and Verb
Step 3:
We mapped these structure features onto the language trees. This enabled us to see whether these features were co-evolving. In the two trees below, the tree on the left shows two features that aren't co-evolving strongly. The two different variants of the first feature (red and blue squares) do not appear to be linked to the variants of the second feature (red and blue circles).
In contrast, the features on the tree on the right show strong correlated evolution. All the languages that have a red square also have a red circle. Languages 3, 4, and 5 have all evolved into blue squares and circles, which can be identified as a single change on the branch leading to this lineage.
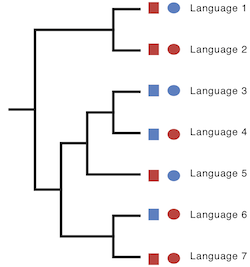
Trees showing uncorrelated evolution between two characters.
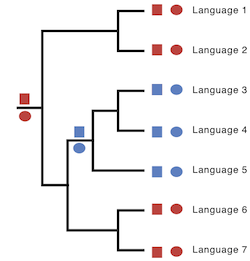
Trees showing the correlated evolution between two characters.
For some more realistic data, in the sample figure of Indo-European languages below you can see that languages that have postpositions (blue squares) tend to have object-verb ordering (blue circles). In contrast languages that have prepositions (red squares) also tend to have verb-object ordering (red circles). You can also see that this pattern appears to show strong phylogenetic signal — linked to the evolutionary history of the languages — as the Romance languages (French, Italian) have the same structure.
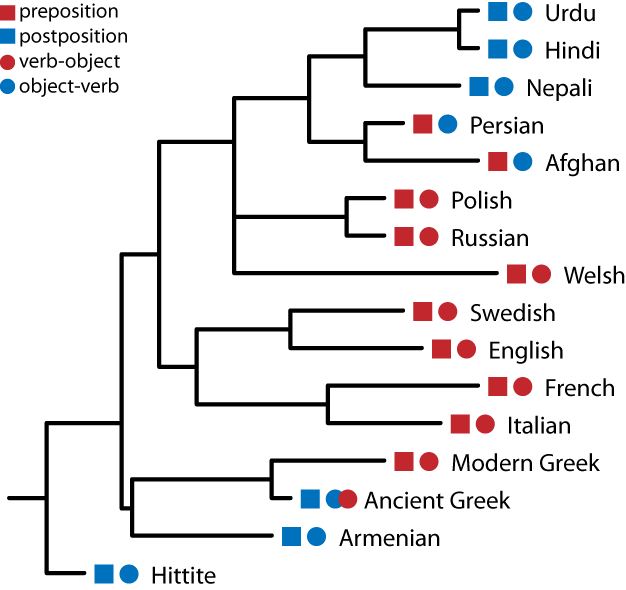
Tree showing the correlated evolution of object/verb order and adpositions.
Step 4:
The next step was to quantify the associations between the features on these trees. To do this we fitted two different models of evolution for each pair of features on each language phylogeny. These models work by calculating the transition rates between the two states of each feature pair along the phylogeny.
The first model was an independent model, which assumes that there is no relationship between the pair of features. In the figure below is a schematic of this model. Whether a language is prepositional or postpositional has no effect on whether the language is a verb-object or an object-verb language.
This model estimates four different rates (in this example):
- the rate at which all languages change from being prepositional to postpositional.
- the rate at which all languages change from being postpositional to prepositional.
- the rate at which all languages change from putting verbs before objects.
- the rate at which all languages change from placing objects before verbs.
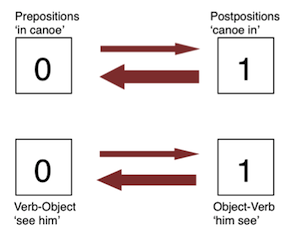
Independent Model of Language Trait Evolution.
The second model was a dependent model, which assumes that there is a relationship between the feature pairs. Under this model the rates of change are allowed to differ according to the languages other feature pair. So, for example, the transition rate is estimated when languages with prepositions change to postpositions — but estimated separately when the language is a verb-object language or when the language is a object-verb language.
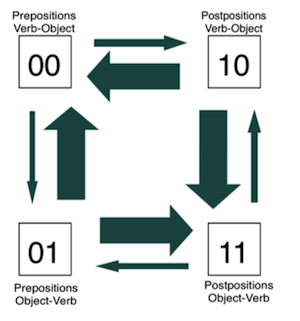
Dependent Model of Language Trait Evolution.
The outcome of fitting these two models is that we can perform a simple test to see which model explains the data the best. If the word-order features are co-evolving, then the best-fitting model will be the dependent model as the transition rates to other features will be contingent on the current state of the language. Please see the supplementary material for a more detailed explanation.
What were the results?
Our major finding is that the word-order features are correlated in many different ways, and these ways vary between language families. The figure below shows the correlations we identified. The black lines indicate strong correlations between word order features, and the size of these lines represent the strength of the correlations. The blue boxes indicate the expected correlations according to the Statistical Universals theory.
For example, in the Austronesian languages, the order of Numerals and Nouns and Adjectives and Nouns is strongly correlated, but this linkage is not identified in any of the other families. Instead there is marked variation between the languages. This is not compatible with either the Generative Linguistics approach or the Statistical Universals approach.
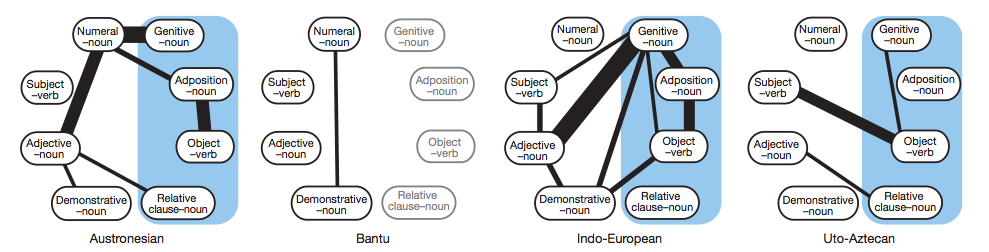
Summary of evolutionary dependencies in word order for four language families. All pairs of characters where the phylogenetic analyses detect a strong dependency are shown with line width proportional to BF values. Following Dryer's reformulation of Greenberg's word-order universals, we expected dependencies between all the features in the blue shaded area. In the case of the Bantu language family, four invariant features (indicated in grey) were excluded from the analyses.
What are the broader implications?
These family-specific linkages suggest that language structure is not set by innate features of the cognitive language parser (as suggested by the generativists), or by some over-riding concern to "harmonize" word-order (as suggested by the statistical universalists). Instead language structure evolves by exploring alternative ways to construct coherent language systems. Languages are instead the product of cultural evolution, canalized by the systems that have evolved during diversification, so that future states lie in an evolutionary landscape with channels and basins of attraction that are specific to linguistic lineages.
One of the main implications here is that to really understand how languages have evolved, we need to understand the range of diversity in human languages. With one language on average going extinct every two weeks, the ability to understand this is rapidly being lost.
Frequently Asked Questions:
-
Why did you use basic vocabulary data to build the original trees?:
Basic vocabulary (e.g. words for body parts, kinship terms, simple verbs etc) was used as these items of lexicon are resistant to being borrowed between languages and stable over time and are closely linked to population history.
In each of the four language families the homologous (cognate) items of basic vocabulary were identified using systematic sound correspondences following the linguistic comparative method. We encoded these sets of cognate words into binary characters representing the presence or absence of each cognate set in each language.
-
What does MCMC mean?
The methods we used to estimate the language phylogenies and to infer the correlations are implemented using Markov Chain Monte Carlo. These methods sample from the posterior probability distribution.
'Monte Carlo' refers to a random sampling method, and a 'Markov Chain' is a process which draws each sample from the probability distribution of the previous state. This method starts with a tree (usually randomly generated) and permutes it in some fashion (e.g. changing the topology, branch lengths or model parameters) — this is the Markov Chain process.
The chain preferentially samples trees from this distribution according to how well they explain the data — the Monto Carlo process. If run long enough the chain provides a representative sample of the most probable trees. There are two further considerations in the use of Bayesian MCMC methods. First, the initial trees sampled are heavily contingent on the model's starting parameters (i.e. the priors). To avoid this early samples in an MCMC run are usually discarded as 'burn-in'. Second, each successive tree in an MCMC run is a permutation of the previous one due to the nature of the Markov Chain process (i.e. tree 2 is tree 1 with a branch moved or a change in branch length, etc). This means that each tree is highly correlated with its neighbors. To avoid this auto-correlation, and thus make each sample statistically independent, it is common to only keep every 1,000th or 10,000th tree from the post-burn-in set of trees.
This whole process is explained in more detail in our paper Austronesian language phylogenies: Myths and misconceptions about Bayesian computational methods .
